Pseudo-LiDAR from Visual Depth Estimation:Bridiging the Gap in 3D Object Detection for Automnomous Driving
1. Abstract
최근에 고가의 3차원 데이터를 인식하는 LiDAR 기술을 이용하여 3D object detection에서 높은 정확도를 보이고 있습니다. 그런데 저렴한 monocular 카메라나 stereo 카메라를 통해서 생성된 이미지 기반 object detection은 LiDAR 데이터에 비해 낮은 정확도를 갖고 있습니다. 이 논문에서는 이러한 detection 성능이 데이터의 퀄리티가 아니라 데이터의 표현 방식(representation)에 있다고 주장하고 있습니다. 저자들은 이미지 기반의 depth map을 pseudo-Lidar 기반으로 변환(Lidar 데이터 방식으로 모사)하여 3d object detection 성능을 높이려는 노력을 하였습니다.
2. Introduction
현존하는 3D object detection 알고리즘은 크게 LiDAR(Lidar Detection and Ranging) 에 의존하는데 그 이유는 3차원 데이터를 정확하게 추출하기 때문입니다. 비록 Detection 정확도 측면에서는 LiDAR를 쓰는 것이 적합 하나 여러가지 이유로 이 방식을 대체하기를 원하고 있습니다. 첫 번째 이유는 LiDAR 의 가격 때문입니다. 두번 째는 하나의 장비에 지나치게 의존하면서 생기는 안정성 문제(특히 장비의 고장으로 이를 보완할 장비 필요성)입니다. 따라서 광학 카메라(monocular 혹은 stereo 카메라)를 통한 이미지 기반 데이터를 이용하는 것이 필요하다고 할 수 있습니다.
최신 알고리즘(KITTIbenchmark 기준) 중에 car detection 성능(3D average precision) 을 높이기 위해 LiDAR 와 monocular 이미지 데이터를 사용한 센서 퓨전을 통하여 66% AP에서 73% AP로 올렸다고 주장하고 있습니다. 대조적으로 이미지 기반의 3D deteciton 성능은 10% AP 라고 합니다. 이것에 대한 원인은 이미지 기반의 depth estimation일 수 있습니다.

위의 그림 1(Figure 1) 를 보시면 LiDAR로 생성된 3D point cloud 데이터와 이미지 기반 최신 stereo depth estimation으로 생성된 pseudo-LiDAR 데이터가 매우 유사하게 일치하는 것(심지어 먼 거리에 있는 물체도 포함)을 확인 할 수 있습니다.
이 논문에서 저자들은 stereo 이미지 데이터, LiDAR를 사용한 3D object detection 성능 차이가 depth estimation에서의 불일치가 아닌 ConvNet-based 3D object detection 알고리즘(stereo-based)에서 적용되는 3D 데이터들의 불완전한 표현방식이라고 주장하고 있습니다. 이것을 평가하기 위하여 stereo-based 3D object detection에 두 단계의 접근방식을 사용하였습니다. 첫번째 단계에서 stereo 혹은 monocular 카메라로 수집된 이미지의 depth map으로 부터 3D point cloud 데이터로 변환하는데 이것을 peudo-LiDAR라고 부르기로 하겠습니다. 결국 LiDAR와 유사한 방식의 데이터로 모사하기 위해서 입니다. 두 번째 단계에서는 이렇게 변환 된 데이터에 Lidar-based 3D depth detection를 적용합니다. 이렇게 3D depth 정보를 pseudo-LiDAR 데이터로 변환하면서 이미지 기반의 3D object detection 알고리즘 성능이 높아졌음을 주장합니다.
이 논문의 contribution은 두 가지로 요약 할 수 있습니다. 첫 번째, stereo-based와 LiDAR-based 3D object detection간의 성능차이의 중요한 윈인에 대해서 실험을 통하여 밝힌 것입니다. 두번째, pesudo-LiDAR 방식의 데이터 표현을 도입하여 stereo-based 3D object detection의 성능을 올렸다는데 있습니다. 이러한 점이 자율주행에 stereo 카메라 사용으로 비용 절감과 안정성 개선에 도움을 준다고 할 수 있을 것입니다.
3. Related Work
1. LiDAR-based 3d object detection
frustum PointNet 알고리즘은 PointNet에 2d object detection network로부터 각각의 frustum proposal를 적용합니다. MV3D 는 LiDAR 데이터를 bird-eyw view(BEV) 와 fronal view로 사영시켜 다시점 특징을 추출합니다. 이러한 알고리즘들은 정확한 3D point 좌표를 가정하고 있기 때문에 point label를 추정하거나 3D 좌표계에서 object 의 위치를 추정하기 위하여 bouding box를 표시해야 합니다.
2. Stereo-and monocular-based depth estimation
이미지 기반의 3D object detection 알고리즘의 핵심은 LiDAR를 대체할 수 있는 depth estimation에 있습니다. 이러한 depth estimation은 monocular 혹은 stereo vision으로 해결 할 수 있습니다. 최근 DORN 같은 알고리즘은 정확한 depth 추정을 위하여 multi-scale-feature와 일반적인 regression을 사용하고 있습니다. stereo vision분야에서는 PSMNet 이 Siamese network를 사용하여 disparity를 추정하고 데이터 정제(refinement)를 위하여 3D convolution를 적용하였습니다.
3. Image-based 3D object detection
이미지 기반의 depth estimation은 3D object detection을 사용하는데 있어서 LiDAR를 대체할 수 있다고 주장합니다. 이러한 알고리즘들은 3D정보를 추출하기 위하여 2D object detection에 추가적으로 기하학적인 제약조건을 부여하였습니다. 특정 알고리즘은 각 픽셀들의 3차원 좌표정보를 추출하기 위하여 stereo-based depth estimation를 사용하였습니다. 그러나 LiDAR 기반의 방법에 비해서는 성능이 뒤떨어지고 있습니다. 다음에 다시 논의하겠지만 이것은 이 알고리즘에서 사용되는 depth 데이터의 표현방식이 원인이라고 합니다.
4. Approach
image based 3D object detection의 많은 장점에도 불구하고, 이미지와 LiDAR-based 접근법에는 많은 차이가 있습니다. 예를 들면 stereo-based 3D depth estimation error는 depth에 quardratic 하게 증가하지만, LiDAR 와 같은 Time-of-Flight(TOF) 기반의 depth estimation error는 linear하게 증가한다고 합니다. 비록 이러한 물리적 차이로 인해서 정확도 차이가 생기는 문제가 있지만 저자들이 주장하는 가장 큰 원인은 데이터 의 quality 혹은 물리적인 특징(데이터 수집으로 인한) 이 아니라 오히려 데이터의 표현 방식(representation) 에 있다고 합니다. 이러한 정확도 개선을 위하여 stereo (혹은 monocula) 이미지로 부터 dense 한 pixel depth 를 estimation 하고 이를 back-projection 하여 3D point cloud로 변환합니다. 이러한 데이터 표현방식(pixel depth -> 3d point cloud)를 pseudo-LiDAR signal로 봄으로써 임의의 LiDAR-based 3D object detection 알고리즘을 적용할 수 있습니다. 이 단계에 대한 전체적인 과정을 그림 2(Figure 2)에서 확인 할 수 있습니다.
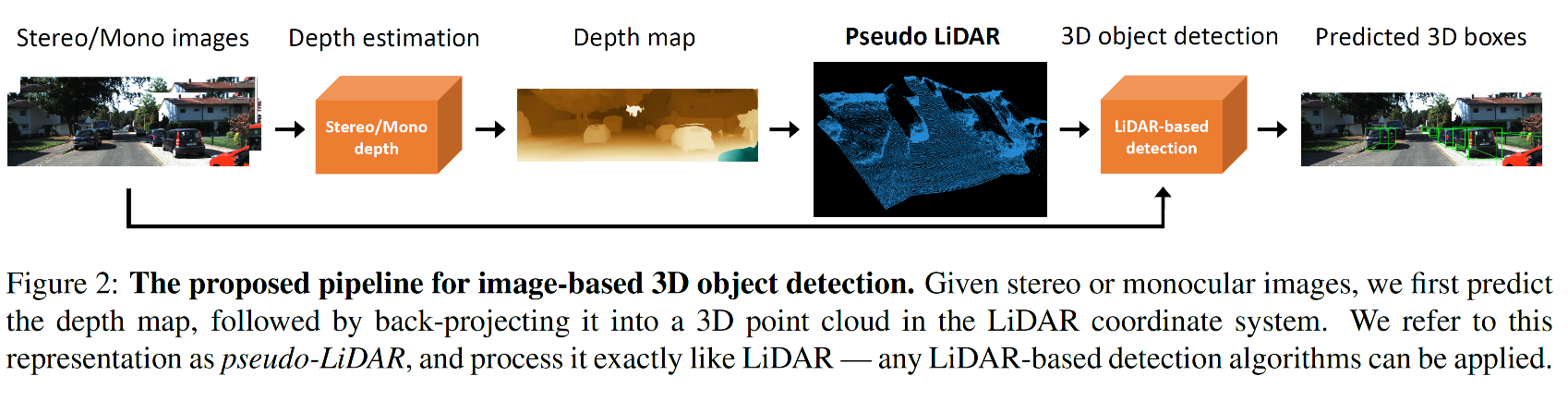
1. Depth estimation
Depth estimation으로 구해지는 depth map D는 다음과 같이 설명되어 있습니다. 자세한 사항은 본 논문과 기타 stereo matching 및 disparity estimation 관련 논문을 참고하시면 좋겠습니다.

2. Pseudo-LiDAR generation
각각의 pixel (u, v) 에 대한 3D 좌표 (x,y, z) 값은 다음과 같이 구합니다.

이런 방식으로 depth-map에 포함된 모든 픽셀에 대한 3D 좌표정보(x,y,z)를 추출하여 3D point cloud 데이터를 복원 할 수 있습니다.
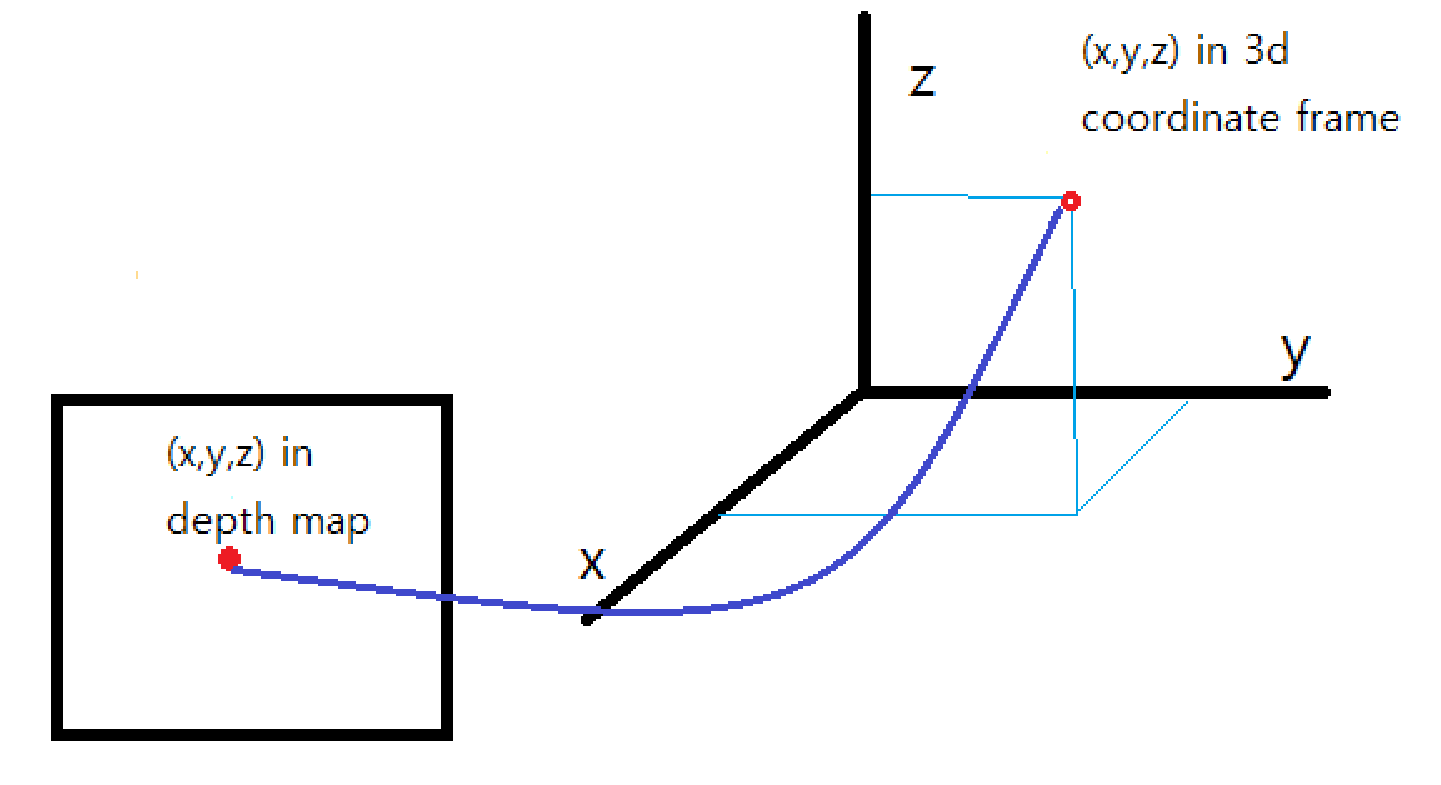
우리는 이러한 3D point cloud 를 pseudo-LiDAR signal로 명명하겠습니다.
3. LiDAR vs. pseudo-LiDAR
현재 존재하는 LiDAR detection 파이프라인에 최대한 호환하기 위해 몇가지 추가적인 post-processing이 pseudo-LiDAR 데이터에 적용되었습니다. 실제 LiDAR 데이터는 특정 범위의 height 에서만 수집되므로 특정 범위를 넘어서는 데이터를 제거하였습니다. 예를 들면 가상의 LiDAR 소스(자율주행 차량의 위에 위치)보다 1M 정도 위에서 수집되는 데이터는 제거하기로 합니다.
Depth estimation 은 pyramid stereo matching network(PSMNet) 을 사용합니다. 그림 1(Figure 1)에서 pseudo-LiDAR points(blue) 는 실제 LiDAR points(yellow)에 상당히 잘 근접해 있음을 확인 할 수 있습니다.
4. 3D object detection
추정된 pseudo-LiDAR points 를 사용하여 자율주행을 위한 LiDAR-based 3D object detetor를 적용할 수 있었습니다. 이러한 작업에서 multimodal 정보(monocular images + LiDAR 등)에 고려하였는데 이것은 실제 visual 정보와 pseudo-LiDAR 데이터를 결합하는 관점에서 자연스러운 판단이라고 생각합니다. 3D object detection을 수행하기 위하여 1) Aggregate View Object Detection(AVOD), 2) frustum PointNet 방식을 선택하였고 두개의 방법으로 나누어 실험을 진행하였습니다.
첫 번째 방법에서는 pseudoi-LiDAR 데이터를 3D point cloud로 다루었습니다. 여기서 frustum PointNet 방식은 2D object detection을 3D 상의 frustum으로 사영(projection) 한 다음, 각각의 3D frustum에서 point-set를 추출하기 위하여 PointNet를 적용합니다.
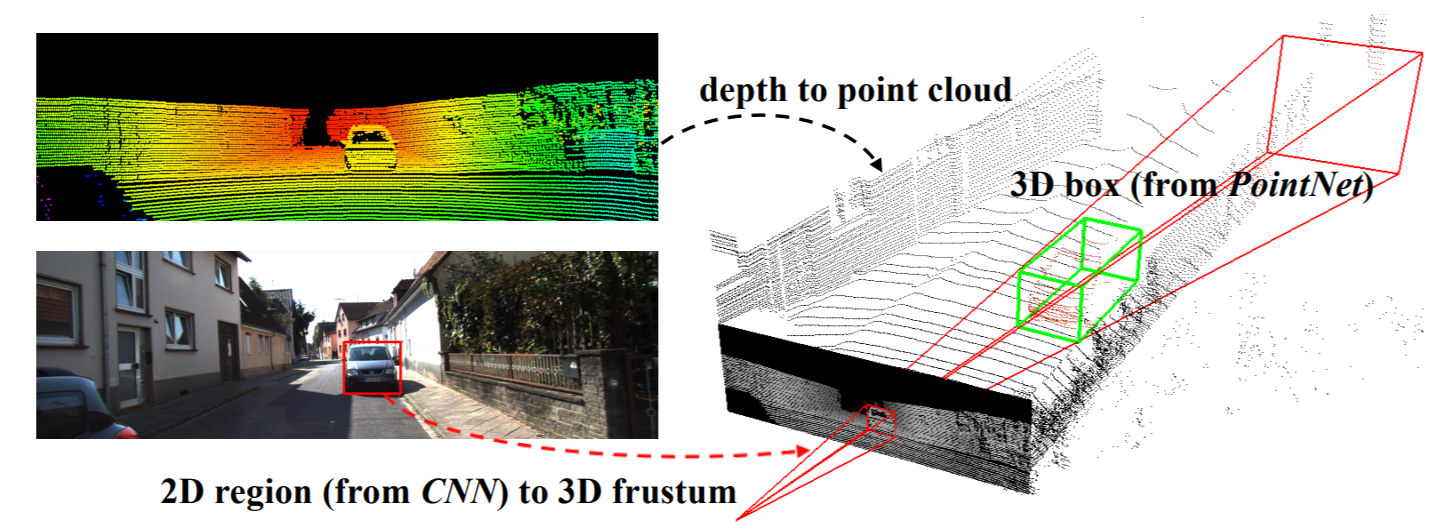
두 번째 방법에서는 Bird`s Eye View(BEV, 조감도) 관점에서 pseudo-LiDAR 정보를 표현 하였습니다. 특히 3D 정보들이 top-down view 에서 2D 이미지로 변환 되었습니다. Width와 Depth정보는 spatial dimension으로 변환 되었고 height 정보는 색상의 채널공간으로 변환 되었습니다. 다음 그림을 확인하시면 이 과정을 쉽게 이해할 수 있습니다. 이러한 BEV 데이터는 AVOD 알고리즘을 사용하였습니다.
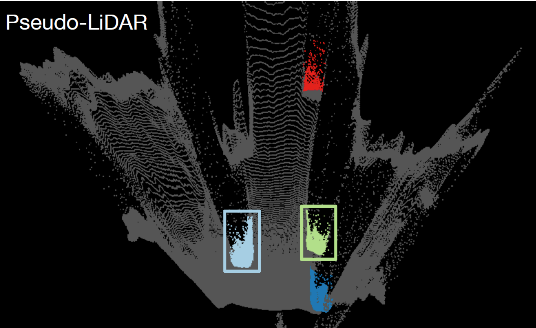
5. Data representation matters
논문의 저자들은 pseudo-LiDAR 데이터는 depth map 정보를 포함하고 있지만 이러한 형태의 데이터가 3D object detection 파이프라인에 더 적합하다고 주장합니다. 2D convolution을 2D 이미지나 depth-map에 적용했을 때 두가지 가정이 필요한데 한 가지 가정은 이미지의 local neighbood 가 의미가 있어야 하고 두 번째는 각 픽셀의 local neighborhood가 동일한 방식으로 처리되어야 합니다. 이러한 두가지 가정이 충족되지 않은 경우에 대해서 예를 들어 본다면 depth-map에서 인접한 두 픽셀 영역이 실제 물리적 거리에서는 매우 먼 거리에 존재하는 경우가 있고, 하나의 object가 여러 스케일의 depth-map의 부분으로 표현되는 경우가 있습니다. 현재 존재하는 2D object detection 알고리즘들은 이러한 조건에서 잘 적용이 안 된다고 합니다.
이와 대조적으로 point cloud 데이터(3D points) 에 3D convolution을 적용하거나 birds’s-eye view slices(BEV, 2D points)의 pixel에 2D convolution를 적용하는 경우는 실제 물리적으로 픽셀 영역이 가까운 부분들입니다. 따라서 이러한 경우의 operation들은 실제 물리적으로 의미가 있고 학습이 더 잘 되거나 정확한 모델을 구성할 수 있습니다. 이러한 점을 확인하기 위해서 그림 3(Figure 3) 과 같은 상황을 가정해서 실험을 진행 하였습니다. 즉 depth-map에 직접 2d convolution 을 적용해 본 것 입니다.
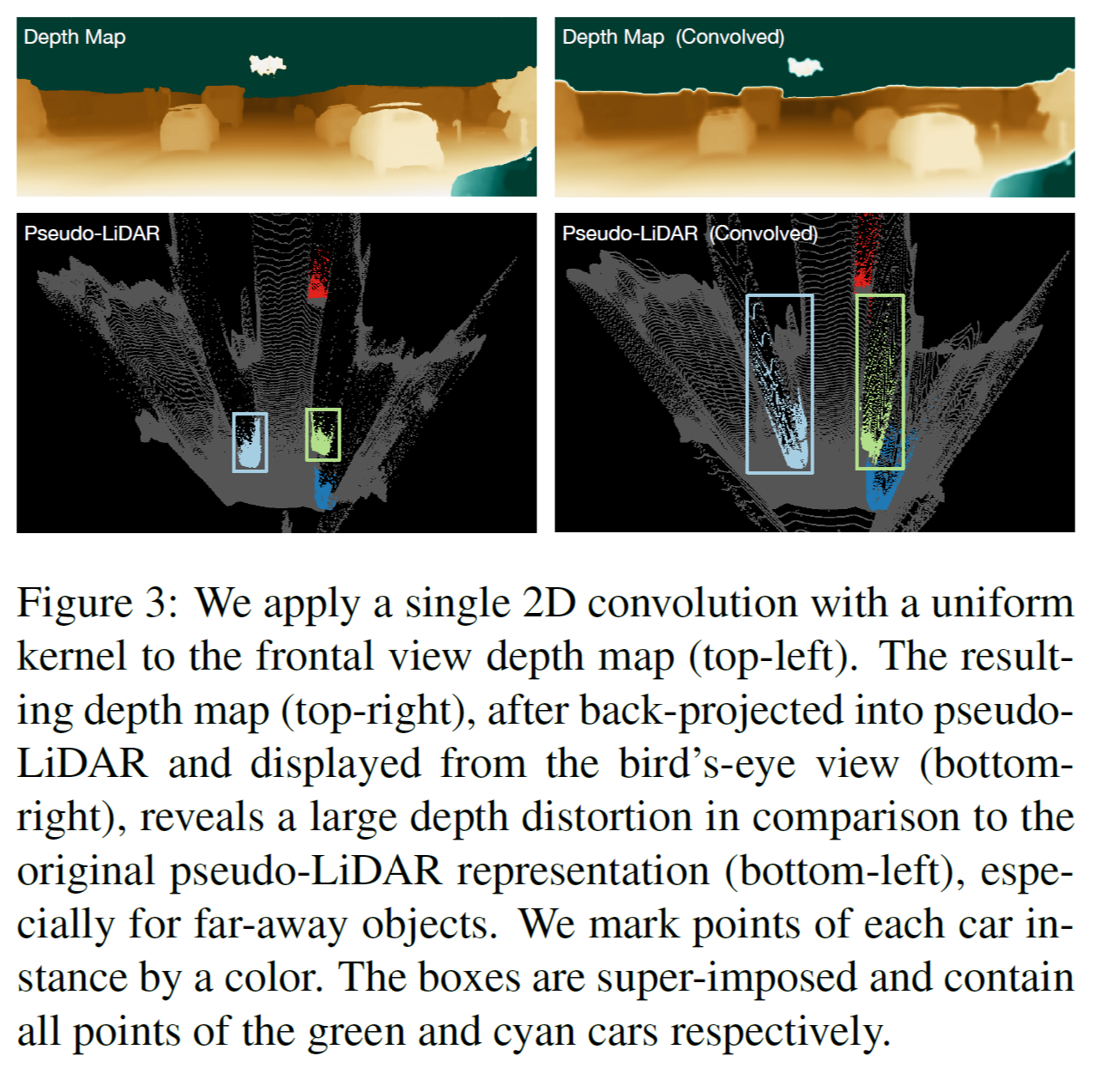
그림 3(Figure 3)의 왼쪽 칼럼에서 original depth-map 과 pseudo-LiDAR 데이터를 확인할 수 있습니다. 자동차들은 특정 색상으로 표시되어 있습니다. 그 다음 11x11 convolution을 depth-map에 적용한 후(그림 3의 오른쪽 위 그림) 다시 새로운 pseudo-LiDAR 데이터로 표현해보면 실제 depth-map의 blurring 된 영역에서 부정확한 데이터 결과가 나오는 것을 확인 할 수 있습니다. 이러한 실험을 통해 depth-map에 2D convolution 적용보다는 그것의 3D 좌표 변환을 통한 pseudo-LiDAR 데이터(bird`s eye view slices) 의 2D convolution 적용이 효과적임을 알 수 있습니다.
5. Experiments
1. Setup
3D object detection로 실험할 때 pseudo-LiDAR를 쓴 경우와 쓰지 않은 경우로 나누어 진행하였습니다.
1.1 Dataset
평가시에 KITTI object detection benchmark 데이터를 사용하였고 총 7,481개의 학습데이터와 7,518장의 테스트 데이터가 포함되 어 있었습니다. KITTI 데이터셋은 Velodyne LiDAR point cloud 데이터로 구성되어 있고, stereo 정보 및 카메라 calibration matix 정 정보(image rectification 및 실제 real coodinate(x,y,z) 을 구하기 위해 필요)가 제공됩니다.
1.2 Metric
3D object detection 과 bird’s eye-view(BEV) object detection에 중점을 두어 실험을 진행하였습니다. 예전 실험 방법의 평가 metric 으로 average-precision (AP) , IOU 임계치 (0.5, 0.7)을 사용합니다.
1.3 Baselines
baseline 알고리즘으로 MONO3D, 3DOP, MLF을 선택하였습니다. MONO3D는 monocular-based, 3DOP는 stereo-based 입니다. 마지막 MLF는 monocular, stereo disparty를 사용합니다.
2. Details of our approch
2.1 Stereo disparity estimation
dense disparity estimation을 하기 위하여 PSMNET, DISPNet, SPS-STEREO 알고리즘을 사용하였습니다.
2.2 Monocular depth estimation
최신 monocual depth estimation을 수행하기 위하여 DORN 알고리즘을 사용하였습니다.
2.3 Pseudo-LiDAR generation
앞의 두 가지 방식의 depth map 데이터에 카메라 calibration 정보를 사용하여 Velodyne 3D point 좌표 방식으로 변환 하였습니다. 이 시스템에서 1 m 이상 height 좌표들은 모두 제거 되어 처리 하였습니다. 여기서 카메라 calibration 정보가 없으면 pseduo-LiDAR 를 구성 할 수 없음에 유의해야 합니다.
2.4 3D object detection
3D object detection을 하기 위해서 Frustum PointNet(F-POINTNET) 과 AVOD 알고리즘을 선택하였습니다. 두 알고리즘들은 LiDAR 와 monocular 이미지를 사용합니다.
6. Experimental results
실험의 핵심적인 부분이 다음의 표 1(Table 1)에 정리 되어 있습니다. 현재는 KITTI 데이터셋을 기준으로 모델의 validation 단계 입니다.
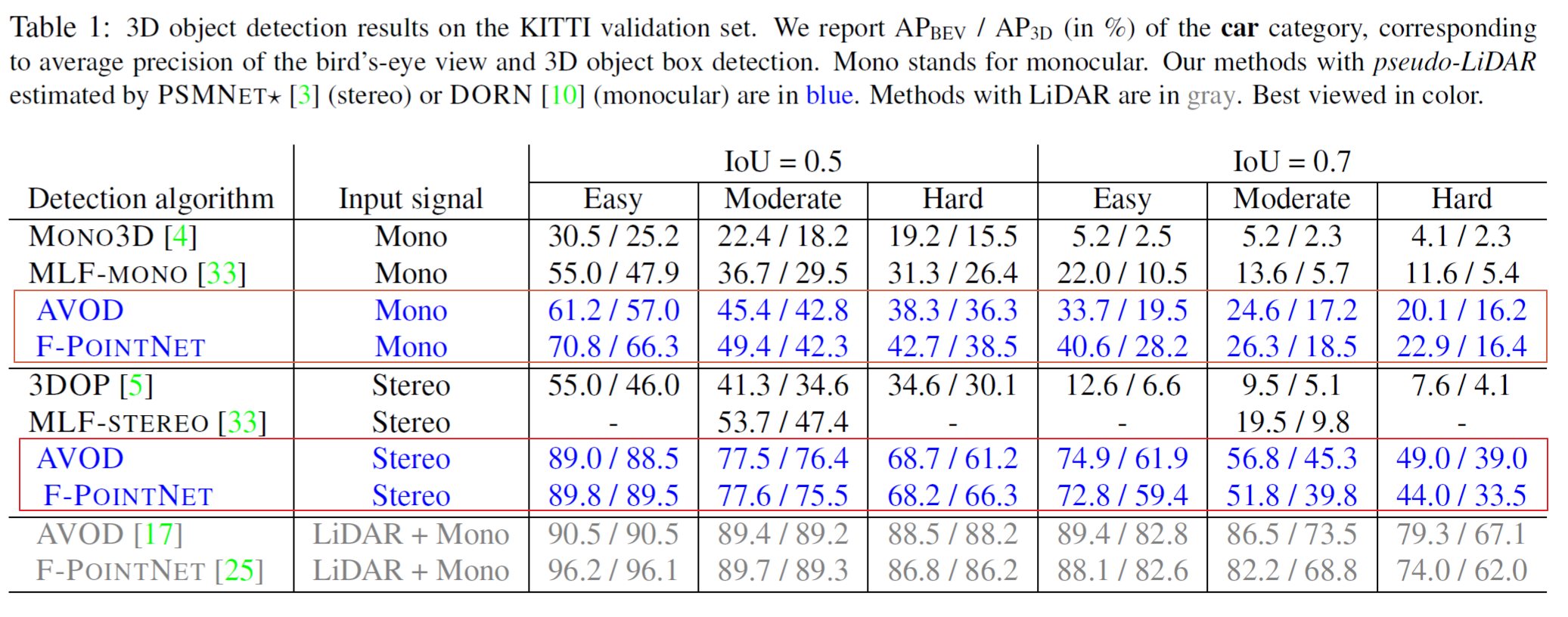
파란색 으로 표시된 부분이 depth-map을 pseudo-LiDAR로 변환 한 후 3D object detection을 수행한 결과 입니다. pseudo-LiDAR 데이터로 변환(3D cloud points, 2D BEV points)한 후 검출한 경우에 모두 성능이 올라간 것을 확인 할 수 있습니다.
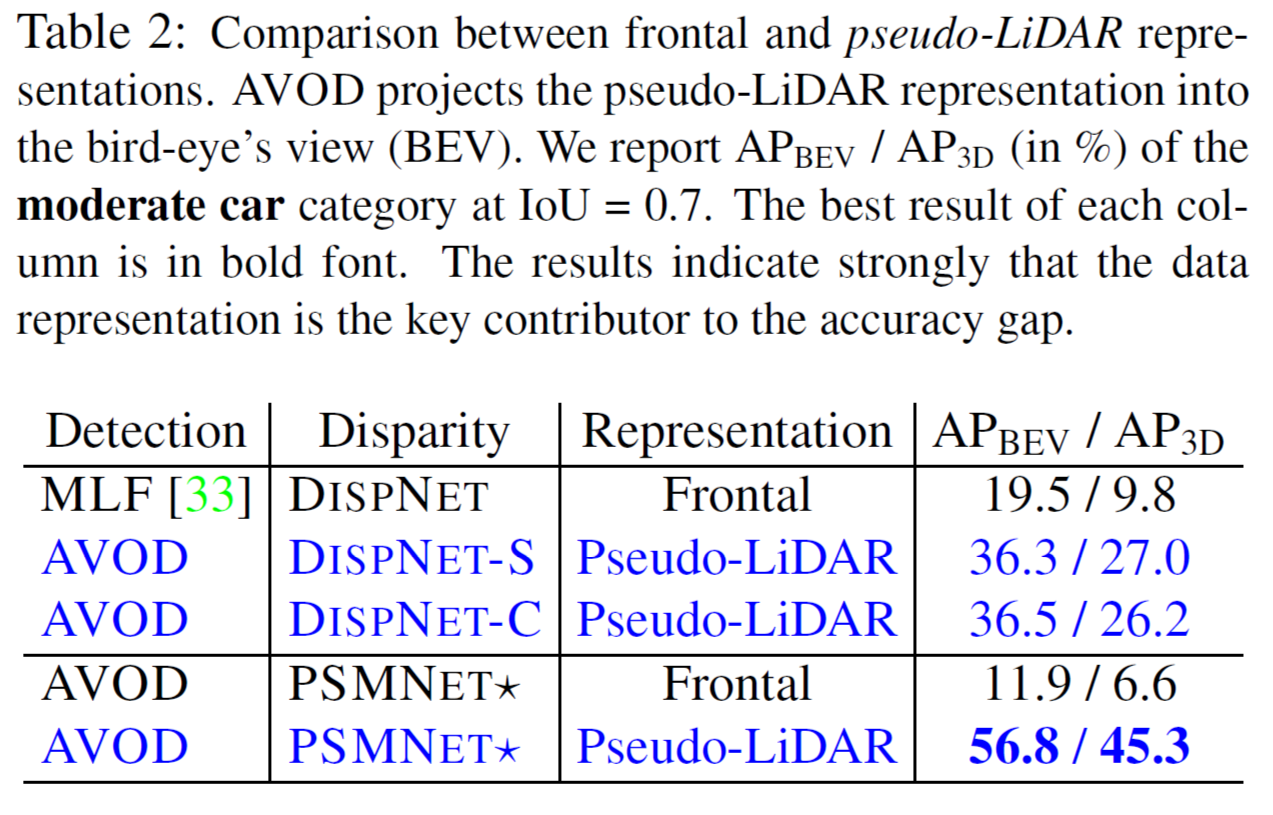
표 2(Table 2) 에서 보면 Frontal 데이터(2D depth-map) 와 pseudo-LiDAR 데이터를 입력으로 했을 때 3D object detection 결과에서 저자들의 데이터 Representaion 방식 (pseudo-LiDAR)으로 검출 성능이 월등히 향상됨을 확인 할 수 있었습니다.
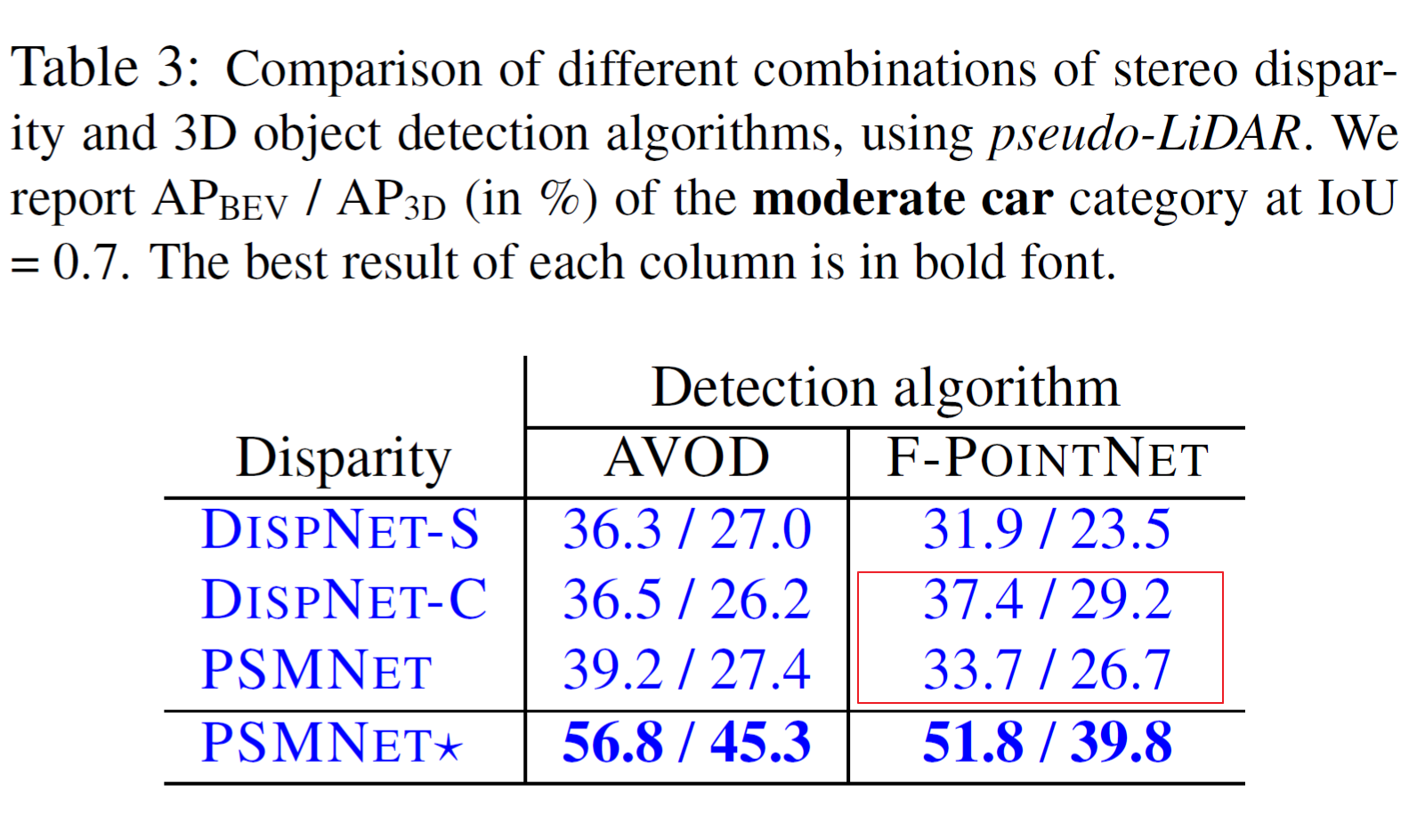
표 3(Table 3)에서는 disparity estimation 정확도가 object detection 성능에 반드시 상관 관계가 없음을 알 수 있습니다. PSMNET이 DISPNET-C보다 disparity estimaiton 정확도가 높지만 F-POINTNET(DISPNET-C)가 F-POINTNET(PSMNET) 보다 더 정확한 검출성능을 보이고 있음을 확인 할 수 있습니다. 원인에 대한 부분은 논문에 상세히 기술되어 있어서 생략하기로 하겠습니다.
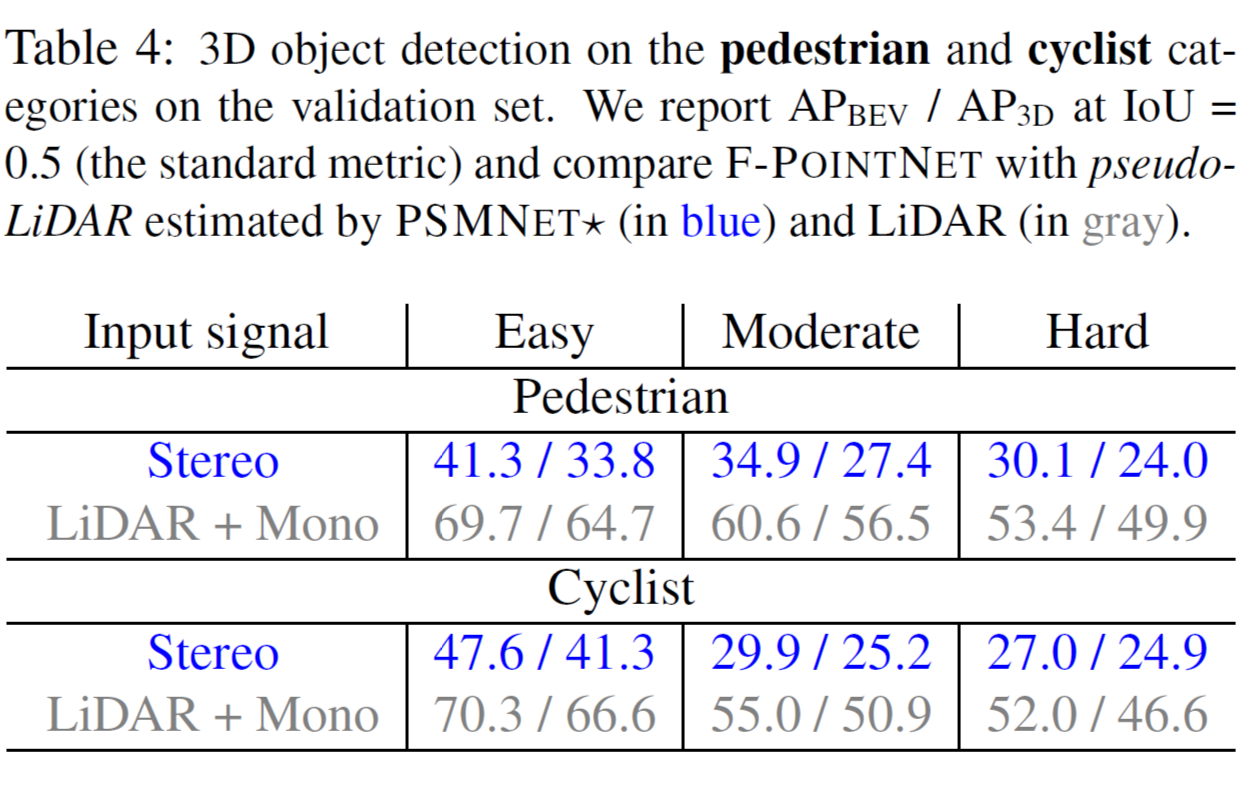
표 4(Figure 4)에서는 LiDAR , Mono depth-map 과 pseudo-LiDAR를 사용한 pedestrian과 cyclist의 3D object detection의 비교입니다.
7. Experiments results on test set
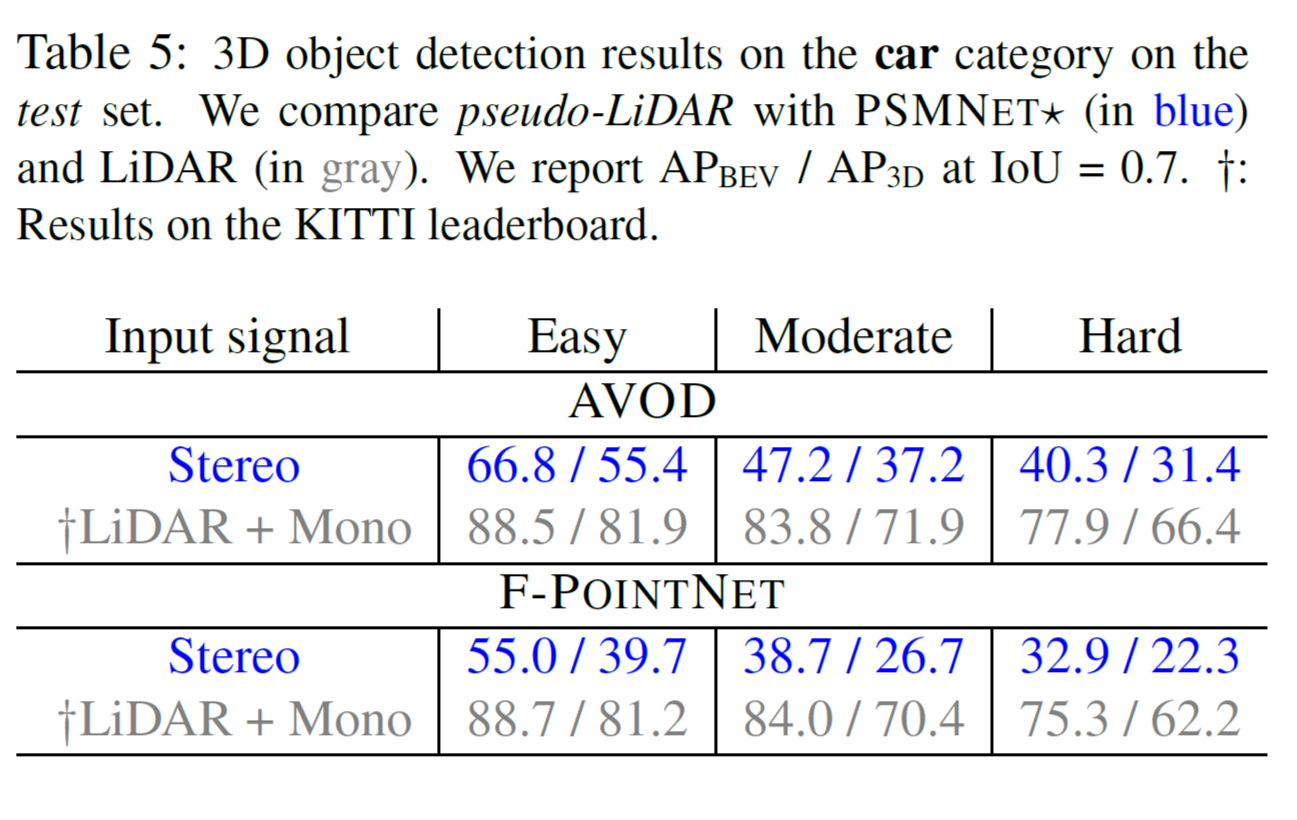
표 5(Figure 5) 에서는 test 수행시 car를 카테고리로 정하여 서로 다른 3D object detection 알고리즘에 대해서 실험한 결과입니다.
validation set 경우의 pseudo-LiDAR와 LiDAR의 유사한 성능 차이에서 알 수 있듯이 실제 실험(test set) 이 validation-data 에 over-fit 되지 않았음을 확인 할 수 있습니다.
8. Visualization
결과 시각화를 그림 4(Figure 4)에 제시하였습니다.

정성적 비교를 위하여 LiDAR 데이터 기반(왼쪽 칼럼), pseudo-LiDAR 기반 (중앙 칼럼) , frontal stereo 기반(오른쪽 칼럼)에 표시되어 있습니다. Ground-Truth Box 위치는 빨강색(red), 검출 결과는 녹색(green)으로 표시되어 있습니다. 육안으로 봐도 LiDAR와 pseudo-LiDAR 기반의 검출은 가까운 물체에서는 매우 정확히 일치하고 있습니다. 하지만 거리가 먼 영역의 검출에서는 depth estimation 이 부정확(저화질 영상에서 먼 거리의 object pixel 정보가 매우 빈약하게 수집)하여 pseudo-LiDAR 기반 검출이 실패하고 있음을 확인할 수 있습니다. 또한 Stereo 방식의 frontal-view-based 검출에서는 가까운 영역에서조차 검출이 부정확함을 알 수 있습니다.

그림 5(Figure 5) 의 오른쪽 이미지에서 pseudo-LiDAR(파란색) 와 LiDAR(노란색)으로 표시되어 잇습니다. 이 결과에서는 pseudo-LiDAR 와 LiDAR points가 상당히 일치 하는 것으로 보입니다. 특히 pseudo-LiDAR 데이터(파란색)가 더 dense 하게 추출되어 있음을 확인 할 수 있습니다.

그림 6(Figure 6)에서는 서로 다른 depth estimation (PSMNET, PSMNet* )로 depth-map을 추출한후 pseudo-LiDAR를 비교한 것입니다. PSMNet의 pseudo-LiDAR 데이터가 거리가 먼 경우에 더 큰 편차(larger deviation)를 갖고 있는 것을 확인 할 수 있습니다.

그림 7 (Figure 7)에서는 검출이 실패하는 경우를 확인 할 수 있습니다. 회색 화살표 영역은 잘 못 검출된 (mislocalization) 부분 이고, 노란색 화살표 영역이 미검출(missed detection) 상황입니다. 오른쪽 아래결과(frontal-view approach) 에서는 가까운 영역에서 조차 검출이 잘못 되고 있음을 알 수 있습니다.

그림 9 (Figure 9) 에서는 object occlusion이 있는 경우 입니다. 오른쪽 아래 이미지에서 노랑색 화살표 부분의 partially occluded 차량 부분에서는 pseudo-LiDAR based 알고리즘의 검출이 실패한 것을 확인할 수 있습니다. 왜냐하면 stereo matching으로 depth estimation을 수행 할 때 object의 occlusion 상황에서는 depth estimation 이 잘 안되기 때문입니다. 반대로 LiDAR 데이터 의 경우에는 object가 잘 검출 되어 있음을 알 수 있습니다. 순수한 이미지 기반 알고리즘을 사용할 때 object occlusion 상황에서는 정확도가 낮아질 수 있다고 판단됩니다.
9. Discussion and Conclusion
논문에서 저자들은 큰 차이를 만드는 것은 단순한 발견이라는 말을 합니다. 이미지와 LiDAR 기반의 3D object detection에서 성능 차이를 줄이기 위한 가장 핵심은 단순히 3D 정보의 표현방식(즉 depth-map의 pseudo-LiDAR 변환)이라고 주장합니다.
현재 강건한 자율주행을 수행하기 위한 LiDAR 장비의 가격은 매우 비싼 것으로 알려져 있습니다. 따라서 고가의 LiDAR 장비가 없다면 자율주행을 수행하는데 필요한 비용을 낮출 수 있습니다. LiDAR가 있는 상황이라고 하더라도 이미지 기반의 object detection은 이득이라고 합니다. 그 이유로는 첫 째, LiDAR 데이터로 학습을 진행한 후 이미지 기반 분류기(image-based classifier)로 미세조정(fine-tuning)을 할 수 있습니다. 두 번째, LiDAR 센서가 오작동 하는 경우 이미지 기반 알고리즘(분류, 검출)들은 보완 역할을 할 수 있습니다.
10. Future work
고화질 stereo 이미지 사용은 먼 거리에 위치한 object 검출에 상당히 중요한 요인입니다. 현재 실험에서는 0.4 megapixel 저화질 카메라로 촬영된 데이터에서 수행한 결과 이기 때문에 최신 카메라(High Resoltion 이미지를 획득할 수 있는) 를 쓴다면 결과는 더 좋아질 여지가 있습니다. 마지막으로 LiDAR와 pseudo-LiDAR를 함께 사용한 sensor fusion으로 3D object detection 성능을 개선 할 수 있을 것으로 보고 있습니다. 왜냐하면 pseudo-LiDAR 데이터는 실제 LiDAR 데이터 보다 dense 하게 데이터가 구성되어 있고(그림1, 그림5, 그림 6)에서 확인가능), 두가지 데이터들은 상호 보완적인 성격을 가지고 있기 때문입니다.